“We don’t need no education” — The Wall
In The Word we see that the words in a language models can be visualized as constellations with precise mathematical relations between each other. And each constellation can also be thought of as a “thinking” entity which takes in other “context” words and redirects to the next word. (Adding itself to the context)
The code to navigate the model and generate content is pretty straightforward, and is not very difficult to develop or run, but the model itself is nothing short of amazing! It is something that a thousand programmers could not have programmed in a thousand years. We haven’t even begun to scratch the surface of understanding what is contained in it. So how did we manage to make these language models?
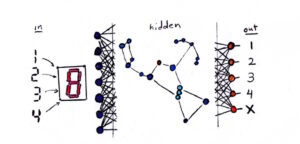
If you have a clear idea of the result you want, but have no training data, you can use “evolution” to teach neural networks. This is the method used for creating bots to beat Super Mario Brothers. The screen is the input, and controller actions are the output. The “hidden” layer is treated as DNA. The DNA is mutated, bred together, and divided into species. Over many generations, only the fittest DNA is kept, and the rest go extinct. The same principle can be used for evolving computer programs. I plan on using my BrainF*ck interpreter to create a laboratory to play around with this concept in PRISM, and I will write about it in depth.
Fortunately, with many zetabytes of content on the Internet, there is no shortage of content to train our model. Where do we start? First you create an hyper-dimensional void, and add all your words. At this point we don’t have the faintest clue where the words should go, however. And we don’t want to place them all at the origin, because that will introduce a bias towards the origin point. So we “explode” the words out, selecting a random hyper-dimensional point for each word.
Next we start working our way through the entire Internet! For every book ever written, every blog post, and every angry rant posted on a forum, we run it through our model nudging the stars to their correct place in the universe. This is where the hard part comes into play. You provide the inputs and the outputs, and use “backpropogation” to turn the knobs in the hidden layer of the neural network. This involves complex coding and advanced mathematics to pull off—people have written thesis papers on the topic, so I won’t be writing about it 😀
So, 64 ZB and a billion dollars later, you get ChatGPT-5. I said we don’t know what’s in it, but we actually do. It is the synthesis of the entirety of human knowledge, organized into a nice, compact mathematical formula.
With this massive undertaking accomplished, the doors are now open to a new form of training. There is no need to start back from the beginning. AI can be tasked with training other AI, which can in turn train other AI… and on and on. What took years to accomplish can now be done in a matter of hours.
Solutions such as OpenAI have thousands of dimensions, vastly exceeding the point of diminishing returns. Reducing dimensions down to several hundred can be 90% as effective, allowing it to run on inexpensive hardware. Stanford’s Alpaca can be trained in an hour and a half and run on a $300 computer! Llama 7B has even been successfully installed and run on a Raspberry Pi!